Shortening the feedback loop with Continuous Integration and Continuous Delivery
-
4503
-
0
-
0
-
0
Every business that has a product or service in continuous development wants to deliver new features as quickly as possible. This is how CI/CD pipelines help shorten the feedback loop.
The process of software delivery can be quite easily obstructed or even halted by release downtimes, testing loops, faulty implementations and so on. In order to minimize the risks and secure a healthy bottom line, the business must make sure their product or service runs well, performs good at scale, is updated frequently and does not crash while
deployed to production. Continuous Delivery and Continuous Integration pipelines are essential for ensuring this.
What is Continuous Integration (CI) and Continuous Delivery (CD)
Before proceeding, we have to define the DevOps terms of Continuous Integration and Continuous Delivery as we use them, to remove any possible misunderstanding.
Continuous Integration — the software delivery practice, when each team member contributes their code to the master branch on a regular basis, to keep the codebase updated at all times.
Due to this approach, the risk of source code inconsistency is minimal, and every developer can synchronize their daily code commits with the team easily. Continuous Integration should be coupled with automated unit testing so that as soon as the code is committed to the mainline, it is tested, pushed to the build server and prepared to be deployed to production immediately.
Continuous Delivery — the software delivery practice, where each update can be shipped to the end users automatically, as soon as the code is built and tested to avoid downtime on release.
What is Continuous Delivery in real life? It is the process of configuring the Terraform and Kubernetes manifests, Ansible playbooks, Jenkins jobs and other kinds of DevOps tooling to:
- Perform automatic virtual infrastructure provisioning,
- Provide a testing server configuration,
- Ensure unit tests execution,
- Send notifications of successful testing completion (or failures),
- Enable packaging of ready source code to push it into production
- Removing downtime due to in-app updates or rolling updates
Thus said, while CI/CD is quite a worthy approach, it becomes hard to implement at scale. For example, in an enterprise environment, there can be dozens of product development teams with hundreds of code commits daily. All this source code must be built and tested on testing and staging servers, before being pushed to production. The developers should be informed if the tests failed or succeeded and should be given the context of the failure to minimize the bug-fixing time.
This all assumes the software development process is straightforward and plain. In reality, things usually differ. A lot. The case of a former Oracle Database developer described on Ycombinator illustrates this well. He had to work on a product well over a decade in development, containing 25 million (!!!) lines of code. Every change, in this case, becomes a step over the bog of interlocking tests, dependencies, and requirements. A minor bug fix can take up to 2 months, with a single new feature implementation taking up to a year. He quit the job with Oracle due to that.
The grim reality of outdated software delivery processes
The common choice for building software delivery pipelines is with the help of a myriad of scripts. Unfortunately, the outcomes of such scripts are usually not too informative. If the automated unit tests fail, it is impossible to understand if the failure happened due to an error in the test or due to the incorrect script execution. The incident reports are usually fragmentary and do not provide an exhaustive picture of the issue root causes. There is usually no possibility to know if the series of tests are completed successfully, or if the 3rd out of 20 failed.
The email or messenger notifications on test success or failure (if any exist) cannot be easily configured to involve only the developers responsible for the new code changes. As the product grows in size and complexity, this turns into an incessant stream of notifications that can flood the recipients completely. In addition, keeping a huge base of scripts up-to-date is a tedious and tiresome task, which draws the resources away from the main effort of delivering more value to the users.
Thus said, many businesses and organizations of all sizes worldwide begin to implement the CI/CD principles, practices, and tools to be able to ship code to end users several times a day, not once half a year.
Main principles of Continuous Integration and Continuous Delivery
Out of pure logic and common sense, we can outline several main principles of continuous deployment:
- Standardized testing pipelines — there is only one way to test and deploy the code
- Instant code testing — the new code batches should be tested at once after they are committed
- Instant artifacts building — new product versions should be built as soon as the new code is successfully tested to be ready for being deployed to the production environment
- Environment-agnostic delivery — the code should be packaged in a way to ensure maximum portability
- Feedback consistency — the outcomes of the CI process should be consistent and uniform across any language runtime
- Short feedback loops — the developers should be able to draw actionable insights from the feedback to apply the fixes as soon as possible
Please note, that there is not yet any question of tooling or level of expertise — these are the plainly visible and straightforward requirements that can benefit any team and any project. The benefits of this approach to CI/CD are quite tangible:
- Rapid delivery of new products and features
- Ease of customer and team onboarding
- Ease of recovery in case of force-majeure
In short, the main goal of CI/CD approach is to remove any friction and unnecessary waste between the commit and deploy of new code. The main issue here is that the developers are often unaware of where their code currently is in the pipeline, as described above.

Transparency: the main benefit of CI/CD
To rectify this situation and implement the CI/CD pipelines the team must answer several important questions:
- When should the feedback be provided?
- How much context does it have to include?
- How often should the feedback be given?
We have mentioned the flaws of incorrect implementation of these processes already:
- Too many notifications might flood your team with irrelevant messages
- Simple constatations of errors are useless if they do not hold any explanatory context
- The messages that are sent after the series of automated tests is completed are useless, if the very first test fails
- The message sent to the wrong contributor is equally useless as the one not sent at all (or even more damaging, as it wastes the time of a professional)
Thus said, the CI/CD pipelines should be implemented using the version control system (VCS) like GitHub and open source DevOps tools like Jenkins, CircleCI or GitlabCI, which allow solving the aforementioned issues. These platforms can be configured to provide exempts of error logs on failure or confirm success on passing the tests. They can get the code contributor tags for each batch separately and inform only the relevant developers. They can be configured to issue warnings as soon as the test fails, not after the whole series is completed to avoid fruitless waiting.
Thus said, the feedback on the code delivery is transparent due to simple, yet effective rules:
- Send only one notification on the failure of a series of tests. The developer that investigates it will discover the rest of the failures in the log and will not be frustrated with spam of multiple identical messages
- Likewise, inform on successful testing merely once
- In the case of test failure, provide enough context to clarify the issue, but not too much to overwhelm the developer with unneeded details
Therefore, if the developer receives a Slack notification that his/her code did not pass the test, we expect the message to include the link to the code Github branch in question, the name of the repository, the number of the pull request and the identifier of the unit test that failed. Such an approach to composing the error reports speeds up the code delivery many times over, as the developers do not have to guess and locate the issue roots.
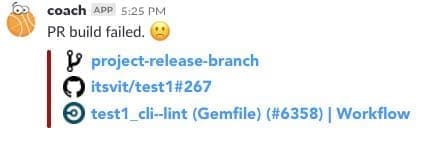
The same principles can be applied to system monitoring, logging and data analysis, operating the self-healing IT infrastructure and other ChatOps use cases. Wherever the software engineers are informed of an issue or task through a messenger notification, the message should be concise and to the point, while containing all the links to the essentials. This approach helps to make sure the true CI/CD is in place — transparency of workflows along with short feedback loops.
Conclusions on shortening the feedback loop with CI/CD tools
IT Svit team uses various open-source DevOps tools in our workflows. Utilizing the capabilities of Jenkins, CircleCI, GitlabCI and other tools, modern DevOps engineers can ensure the fluidity of software delivery, as well as cost-efficiency and lowering the risks of running the infrastructure in production. The essential task here is configuring the given tools to interoperate seamlessly and provide the required feedback data.

This is not a task easily performed, so quality assurance and automation are actually one of IT Svit areas of expertise as one of the top 10 Managed Services Providers worldwide. We can build error-proof, nimble and responsive CI/CD pipelines to empower your value delivery stream. Do you need it? Let us know, we are always ready to help!
