Short guide on how Deep Learning really works
-
5602
-
18
-
4
-
0
Artificial Intelligence (or AI) is the goal many researchers try to reach. Many people consider Deep Learning (DL) as a synonym of AI, while it is not so. Learn how Deep Learning works!
The confusion is mostly caused by the misunderstanding of the definitions of the key components of the process. We will briefly describe each of the basic statements so you can see the differences firsthand.
See also: The future of AI: Deep Learning… or much more?
Artificial Intelligence (AI) was supposed to be the imitation of human consciousness and thinking process by the means of the computer code. However, despite the recent release of Loihi, a self-learning chip from Intel, the current state of data science and AI research is far from reaching the calculational capacities of the human brain. Currently existing AI implementations are based on strict sets of rules and cannot develop individuality, always acting the way they were programmed by their developers.
Deep Learning is the field within the ML domain, which encompasses operating without strict sets of rules, as the machine learning (ML) algorithm should extract the trends and patterns from the vast sets of unstructured data after accomplishing the process of supervised (guided) or unsupervised learning.
Supervised learning stands for the case of labeled data inputs and outputs used in training sets. Thus said, the ML algorithm receives both the input information and the expected output of the process of calculations. If the calculations are incorrect, the ML algorithm makes the adjustments until, after many iterations, the results become acceptably correct. In real life, you are forced to choose an acceptable result on which the iterations will stop. Otherwise, the algorithm may need an infinite number of iterations (time) to achieve 100% accuracy. This type of training can be helpful in case lots of historical data is available (like the weather forecasts).
Unsupervised learning, quite contrary, is the approach to training the ML model using the unstructured data sets, where the types of incoming and resulting data are not known. Such approach helps make predictions based on the currently available data. For instance, such ML model is suitable for analyzing the e-commerce website visitors and predicting what types of visitors are most likely to make an order.
With these terms explained, let’s move on and describe how the Deep Learning really works.
The basics of Deep Learning operations
The main element of a Deep Learning neural network is a layer of computational nodes called “neurons”. Every neuron connects to all of the neurons in the underlying layer. There are such types of layers:
- Input layer of nodes, which receives the information and transfers it to the underlying nodes
- Hidden node layers are the ones where the computations take place
- Output node layer where the results of the computations appear
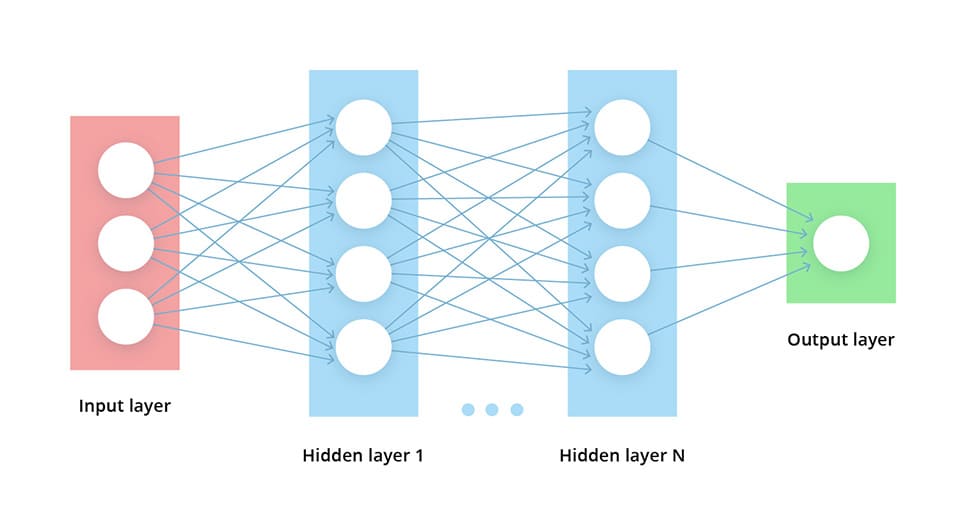
The “deep learning” means the neural network is leveraging at least two hidden layers. By adding more hidden layers the researchers enable more in-depth calculations, yet deploying such networks demands immense amounts of computational power.
How does the algorithm work then? The thing is, each connection has its weight or importance. The initial values of weight are assigned randomly (or according to their perceived importance for the ML model training dataset creator). There is an Activation Function for every neuron that evaluates the way the signal should take, just like in the real human brain. If after the data set is analyzed the results differ from the expected, the weight values for these connections are configured anew and the new iteration is run.
Each iteration yields some results and they differ from the expected ones. The value of the difference between the real outcomes and the AI’s calculated outcomes is called the loss function. We want this function to be as close to zero as possible, meaning the ML algorithm produces the correctly calculated outcome.
Each time we adjust the weight of the connections between the nodes (or neurons) and run the algorithm against the data set, we can see if the next run yielded more accurate results, or did they become even less precise. The function describing how changing the connection importance affects the output accuracy is called the Gradient Descent. By evaluating the results after each iteration, we are able to adjust the weights in small increments and understand the direction to reach the minimum.
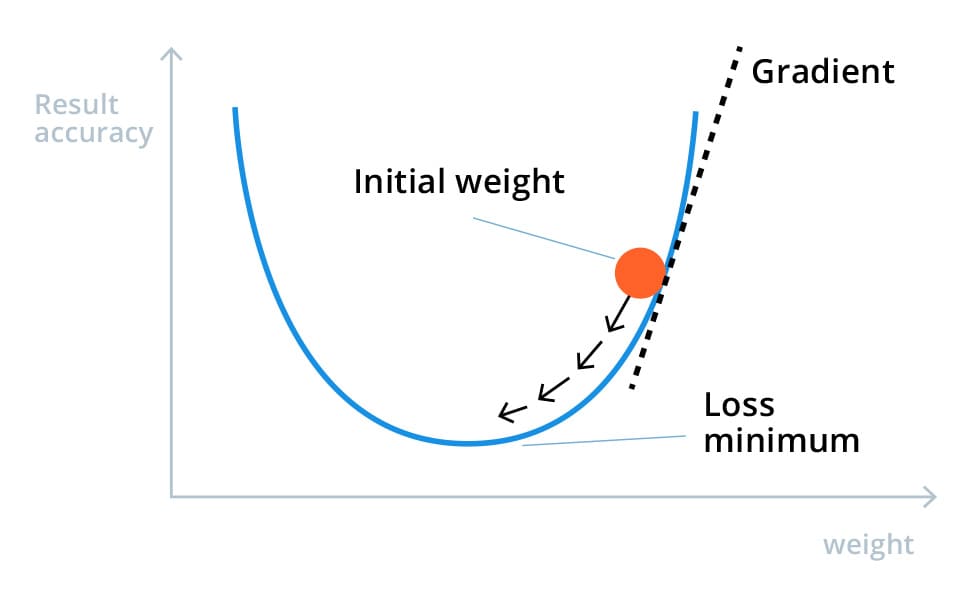
To sum it up, in several iterations the trained Deep Learning model will produce the acceptably accurate results and will be ready to be used in production. This model might still need some calibration while in production though (as the weight of the input factors might change over time), so an experienced ML specialist (or a whole team) is needed to perform the job.
We hope this short guide on how Deep Learning really works will help you grasp the basics quickly. Should you have any more questions — feel free to ask, we are always glad to help!
