How much does your server downtime cost?
-
3468
-
2
-
0
-
0
Everybody and their dogs know that server downtime is bad for business, that it costs you money. There are multiple cases when incorrect software updates or post-release server downtime resulted in huge financial losses for various global enterprises. But how much money are we actually talking about? Today we explore how much your server downtime really costs.
In May 2017, British Airways suffered a huge IT system failure that has lead to a loss of nearly $70 million in ticket reimbursement and hotel expenses, cancellation of flights for 75+ thousand passengers, and losing nearly 3 percent in the AIG stock price.
Financial Times published a list of similar failures, where it mentioned Delta Air system shutdown in 2016, which resulted in a loss of nearly $150 million and the cancellation of 2,300 flights, affecting several hundred thousand passengers.
HSBC Bank had an unexpected crash amid the update of its systems in 2015, which lead to an inability to cash their paychecks for its customers — and just before the holiday weekend, no less. Royal Bank of Scotland has a history of post-update software failures and was fined for $72 million back in 2012 after such an outage has affected 600,00 of its customers.
To wrap it up, according to a Gartner research of the downtime cost conducted in 2014, businesses lose $5,600 a minute on average during downtime. But aren’t these numbers a bit outdated, you might ask? DevOps makes all the things better, you might say! It results in a more smooth update process and more predictable software delivery, isn’t it?
Well, Facebook is one of the unicorns, it uses the very best cloud and DevOps technologies, it takes its pride in smooth in-app updates and uninterrupted end-user availability… and Facebook lost $90,000,000 due to a 14-hour-long blackout in March 2019. For Fortune1000 companies, the cost of an hour of downtime can reach $1 million, IDC report states. A Statista report further elaborates that while for 25% of respondents a cost of an hour of downtime is between $100,000 and $400,000, a whopping 15% reported their system costs being above $5,000,000 per hour!
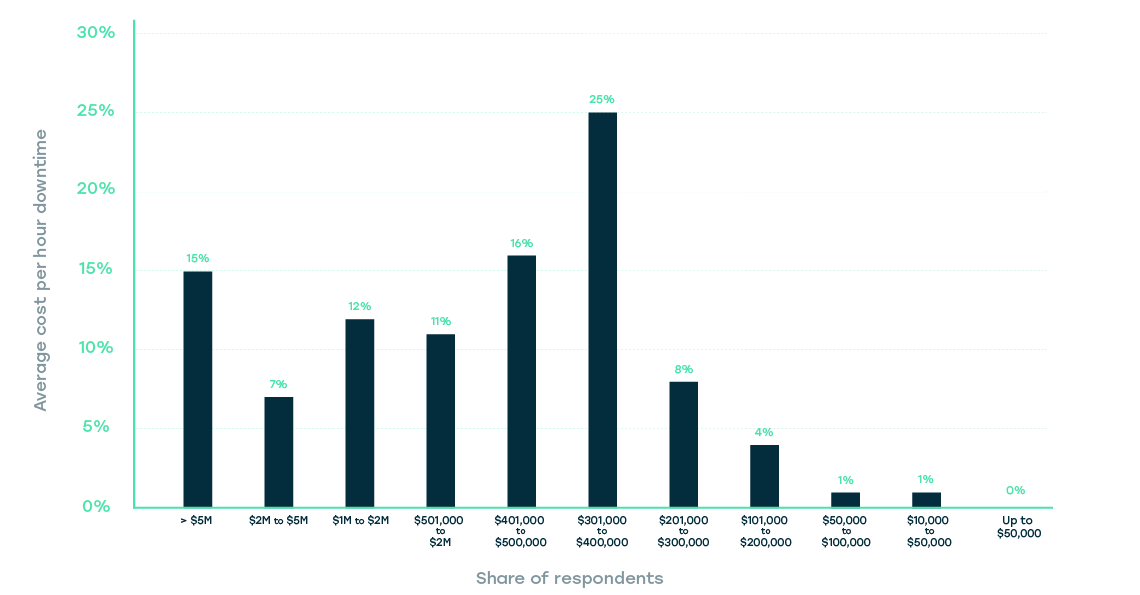
However, aside from direct financial losses, the cost of downtime includes a variety of other factors. As a report from Atlassian states, there are many more factors in play here:
- business disruption damage, leading to customer churn and reputational damage
- end-user productivity and potential revenue loss
- internal productivity loss of all the teams involved in handling the situation — from IT to PR and marketing. Carnegie-Melon research states that up to 23 minutes are needed to get back to your work after an interruption and the cognitive function decreases by 20%
- SLA breaches, government fines and other regulatory fees, along with court litigation and settlements that might arise from any system outage
- The last but not the least important factor here is employee retention, as discouraged employees tend to leave, and replacing a specialist costs up to 1/3rd of their annual wage.
As you can see, this data from 2019 clearly indicates that quite a large segment of Fortune1000 organizations surveyed experience costly outages. But pardon me, 88% of these same Fortune1000 organizations have reported steady and ever-increasing DevOps adoption (you surely know Forrested proclaimed 2017 the year of Enterprise DevOps when 50+% of this list reported they were actively using or adopting DevOps workflows). Thus said, either DevOps doesn’t work (but we know it is), or these companies’ reports are like rose sunglasses.
The latter is more plausible, as we all know that the things down there in the corporate thickets are rarely as shiny as the executives want us to believe. There are several factors that hinder the DevOps adoption in earnest:
- Cultural resistance
- Process fragmentation
- Lack of managerial support
In addition, when a company invests dozens of millions in its infrastructure, processes and tools, it is very hard to drop that all and adopt DevOps tools and workflows. This is the reason behind at least 80% of DevOps adoption fails.
If you want to do DevOps in earnest — you’d better invest in skills and tools like Terraform, Kubernetes, Docker, Ansible, Jenkins, ELK, Prometheus& Grafana and many others. Needless to say, most of the DevOps tools are open-source, so you will be saving immensely over the long run — but the initial transition can be quite overwhelming.
There is another great result of using DevOps — when your IT operations are automated, you can deploy a Machine learning model to do predictive analytics. Such a model will define normal operational patterns and monitor your systems. If the first signs of a possible failure appear, it will immediately enact one of several possible countermeasures scenarios — and reduce the risk of downtime even occurring.

Conclusions: instead of minimizing the downtime cost, minimize the chance of it happening!
To wrap the things up, the companies that run IT infrastructures are bound to have some failures. These can result in huge revenue losses and associated expenses, so the cost of downtime can be as high as $5 million per hour! However, using true DevOps tools and workflows helps minimize the risks of such a downtime even occurring, so it is worth investing in! By utilizing skilled DevOps services to enable predictive analytics you can even build self-healing infrastructures with modules able to restart after failure and multiple replicas of key components — so you will never experience downtime again.
It seems too good to be true? Let us show you how it can be done!
