Deep Learning summary for 2017: Machine Perception Developments
-
4857
-
0
-
5
-
0
In one of our recent articles we told about the advances in Deep Learning text and speech applications. An equally prominent domain is the DL algorithms for machine perception.
Machine perception is the field of deep learning study related to machines not merely reading the pictures, like the computer vision does, but to also comprehending them, like perceiving the meaning of various signs, answering questions about the image content, drawing sketches, aging faces, and even protecting the websites from captcha bypassers — or fooling the face recognition systems…
Google Maps improvements with OCR
Google Brain team has developed a new Optical Character Recognition (OCR) algorithm to improve Google Maps and Street View services with better road sign recognition capabilities. Due to this they were able to make the road signs better visible on more than 80 billion photographs.
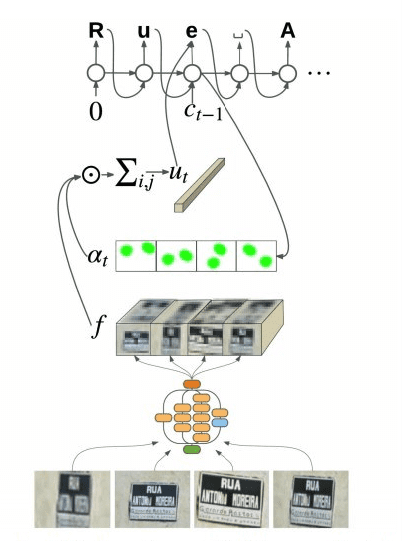
The resulting model is also able to concentrate on the shop signs automatically, filtering them out of the unneeded visual noise on the photos.
Visual reasoning solved
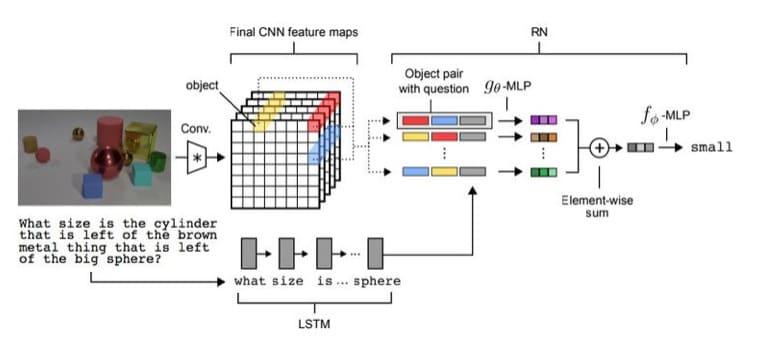
One of the less trivial tasks for a neural network includes answering a question based on the image contents. For example, the DL model must answer if there are any rubber objects sized as the metal cylinder on this picture. Previously, the rate of correct answers reached ⅔ at max.

2017 showed yet another achievement for Google Deepmind team, who taught their model to answer such questions correctly in 95,5% of cases.
Pix2Code: create your website layout directly from the pictures
Uizard team has unveiled a great tool that can transform the experience of website creation. Their neural network transforms the GUI screenshots into the website layout code with 77% accuracy.

Though this still is the research project and the tool is not production-ready, the possibilities it promises to provide are incredible.
ScetchRNN: Arithmetics in pictures drawn by the DL model
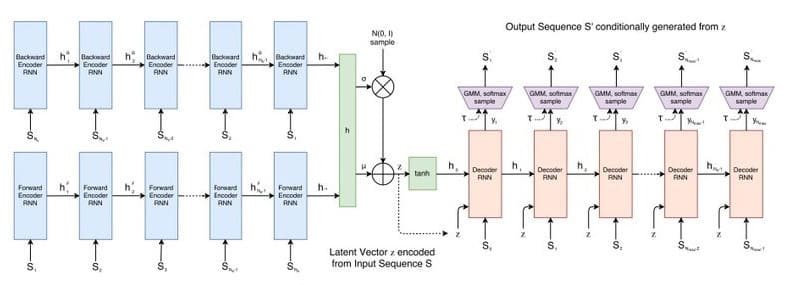
Did you see a page titled Quick, Draw!, where the visitors were tasked with drawing a picture in 20 seconds? This was a project from Google, aimed at teaching the machines to draw.

The resulting data set of 70,000 vector images is publicly available for training your own Variational AutoEncoder (VAE) using RNN as the encoding/decoding tool.
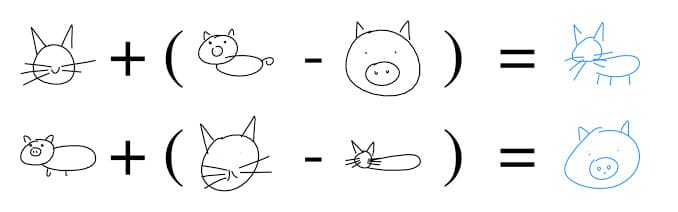
Such algorithms can perform vector arithmetics for drawing catswines, for instance)
Generative Adversarial Networks (GANs)
2017 was a hot year in the field of GAN research, as many researchers were able to find a much better balance between generator and discriminator networks.
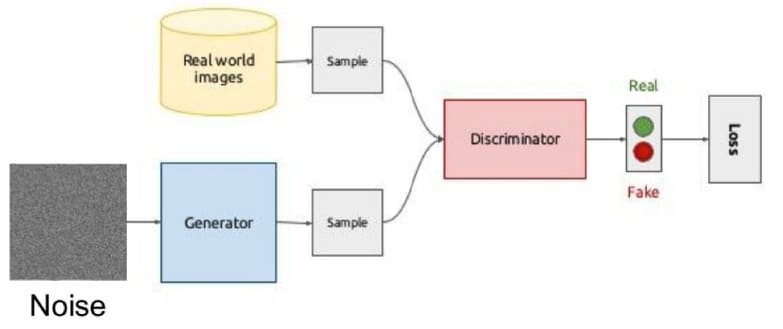
The result of training such a model is that it becomes able to choose the best-quality images (the most common application is selecting the best of the series of face photos, rooms or landscape photos).

These algorithms also excel in vector arithmetics:

Face aging with GANs
We are sure you noticed an eruption of face-adjusting apps, aging being the most popular ones. Make a selphie and watch your face becoming 40, 50, 60, 70, 80-years-old. This is done by introducing a configurable parameter while training a GAN, and adjusting it in the defined direction.
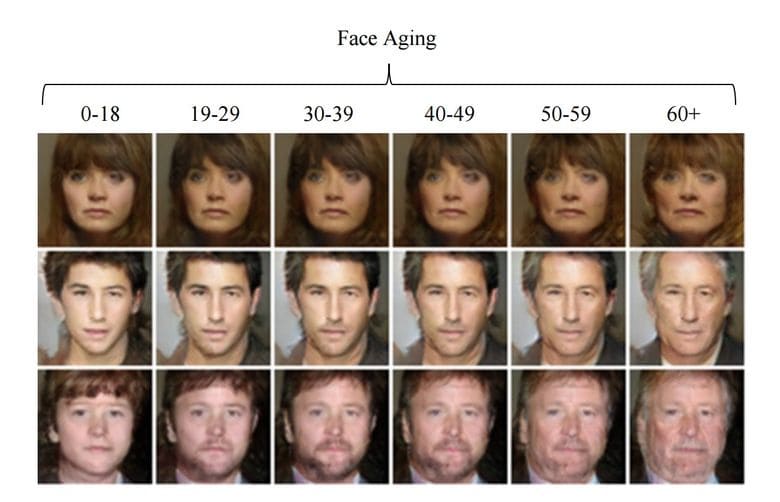
This specific face aging algorithm using GANs was trained using huge collection of IMDB photos of various celebrities throughout their lives.
Photo improvement
Google has also been able to make another use of GAN — as a system capable of creating and improving the professional-level photos. The logic was the same, as the generator tried to improve bad photos (professional quality photos impaired using special filters), while the discriminator tried to sort them from the real world photos of professional quality.
The trained model then searched across a myriad of Google maps sceneries and made a variety of photos of professional or nearly professional quality.
Text-based picture choice
One of the most impressive cases of GANs application lies within their ability to choose the picture describing the text fragment. If the textual input is fed to both a conditional GAN generator and a discriminator GAN, the system can check if the text corresponds the picture, after being trained by consuming fake text-picture pairs.
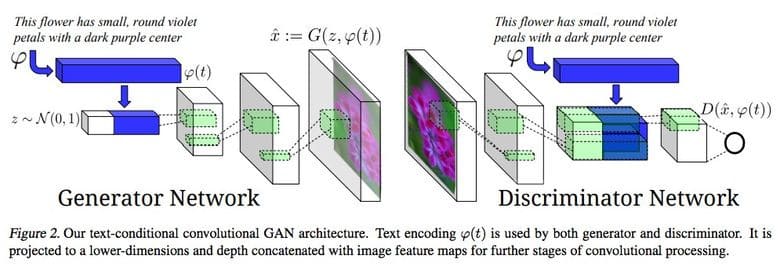
Pix2Pix project evolution
Surely you’ve heard of the late-2016 release of a Pix2Pix image translation using GAN. It allowed creating a map using a satellite photo or draw a building facade using labels, along with several other use cases.
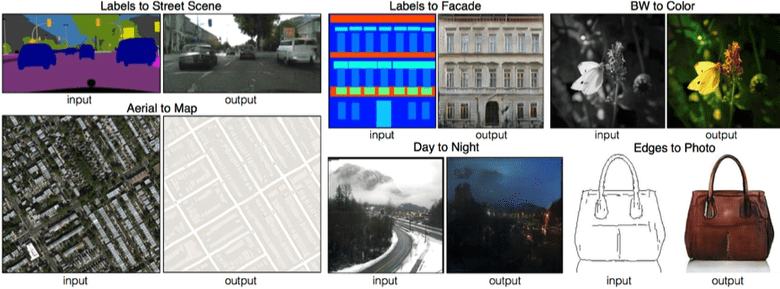
The latest release of Pix2Pix project on GitHub uses the new PatchGAN as a discriminator, where a picture is split into n parts and each one is evaluated if it is true or fake. The online demo of this DL model capabilities show a truly astounding potential!
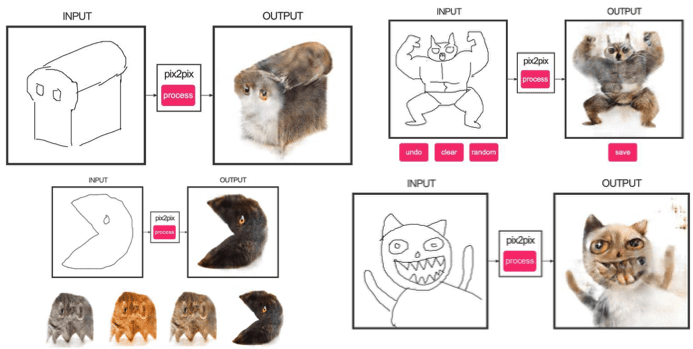
CycleGAN for creating a ZebraPutin!
Another neat application for GANs was sitting right around the corner — what about merging the images that have no direct pairs for their domains? An unpaired image-to-image translation or CycleGAN promises great capabilities for styling and object transfiguration.

The algorithm uses cyclic consistency loss, thus the title:
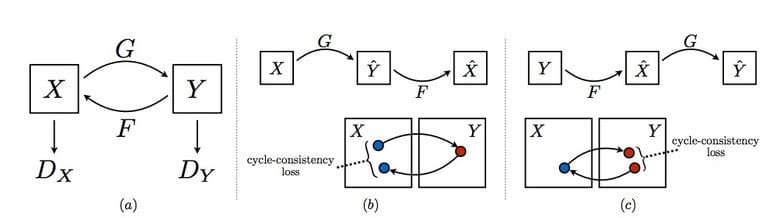
This also allows for combining data from different sets to create a realistic mapping:

Cybersecurity using machine perception
As you might have already known, adding some noise to the picture spoofs it for the GAN. While remaining nearly the same for the human eye, such picture causes the algorithm to go haywire:

Why is this important? Firstly, we can protect our websites by adding such noise to captcha and protect it from various captcha bypassing tools. Secondly, by exploiting the flaws like these the hackers can gain access to various IoT applications, like face recognition systems or self-piloting cars.

Therefore, developing Deep Learning algorithms both capable to deliver the result and able to withstand the attack is becoming the task of utmost importance. There are several libraries already developed to attack and defend neural networks, like cleverhans and foolbox, created to participate in the NIPS competition 2017.
Conclusions on the machine perception developments in 2017
Machine perception projects were a significant part of the Deep Learning field in 2017, opening a plethora of new capabilities. From fiddling with face aging for fun and all the way up to serious issues like website captcha protection and Google Map improvements, this year was rich with fascinating discoveries.
In the third part of our Deep Learning summary series we will describe the advancements in the field of reinforced learning and several other projects. See you soon, and if you have any questions or suggestions regarding Deep Learning projects — drop us a line, we are always glad to help!
Source: Habrahabr.ru
