Big Data Scraping vs Web Data Crawling
-
5306
-
0
-
0
-
0
Big Data analytics, machine learning, search engine indexing and many more fields of modern data operations require data crawling and scraping. The point is, they are not the same things!
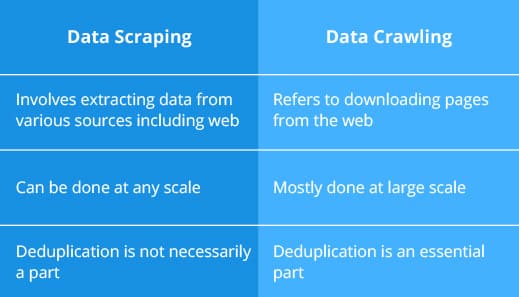
It is important to understand from the very beginning that data scraping is a process of a specific data extraction that can happen anywhere — on the web, inside the on-prem database, inside any base of records or spreadsheets. More importantly, data scraping can be sometimes done manually.
Quite contrary, web data crawling is a process of mapping all the specific ONLINE resources for further extraction of ALL the relevant information. It must be done by specially-created crawlers (search robots) that will follow all the URLs, indexing the essential data on the pages and listing all the relevant URLs it meets along the way. Once the crawler finishes its work, the data can be scraped according to predefined requirements (ignoring robots.txt, extracting specific data like current stock prices, real estate listings, etc.)
Data crawling involves certain degree of scrapping, like saving all the keywords, the images and the URLs of the web page and has certain limitations. For example, the same blogpost can be published on multiple resources, resulting in several duplicates of the same data being indexed. Therefore, a deduplication of the data is required (by the publication date, for example, in order to leave only the first publication), yet it has its own perils.
Thus said, there are quite a few distinct differences between big data scraping and web data crawling:
Most importantly, data scraping is relatively easy to configure, though a decent data science background is still recommended to ensure the success of the job. These are straightforward tools that can be configured to do a specific task on any scale, ignoring and overcoming all the obstacles along the way.
Web crawling, on the other hand, demands sophisticated calibration of the crawlers to ensure maximum coverage of all the pages required. Thus said, the crawlers must comply with all the demands of the servers in order to not to crawl them to often and not to crawl the pages the website admins excluded from indexing, etc. Therefore, efficient web crawling is possible only by hiring a team of professionals to do the job.
Conclusions on the differences between big data scraping and web data crawling
We hope our article was helped you grasp the differences between big data scraping and web data crawling. What do you think on the matter? Did we make any mistake in our explanations? Please share your thoughts and experiences on the matter! Should you have any inquiries — we are always glad to assist!
