Cost of hiring a DevOps engineer in 2024
-
1182
-
21
-
11
-
0
The adoption of DevOps practices is a strategic move. However, it can be a challenge to choose a safe, efficient, and most importantly, financially reasonable solution. In this article, we will dive into the key factors that influence the compensation of a DevOps engineer and weigh the most favorable hiring offers.
Why Hire a DevOps Engineer?
Businesses are facing increasing pressure to deliver software products and services quickly and reliably. To meet these requirements, many organizations are adopting DevOps practices. But let’s see some benefits and whether DevOps is really what you need.
Accelerated Deployment and Time-to-Market
DevOps engineers play a vital role in streamlining software development and deployment processes, allowing businesses to release products and updates faster. According to a survey by Puppet, organizations that have adopted DevOps practices experience 200 times more frequent deployments and significantly shorter lead times. Hiring a DevOps engineer can help your business take advantage of these benefits and gain a competitive edge in the market.
Increased Collaboration and Efficiency
DevOps is not solely about technology. It promotes a cultural shift that emphasizes collaboration and effective communication between development and operations teams. By bridging the gap between these traditionally siloed functions, a DevOps engineer fosters a unified and cohesive working environment.

Enhanced Stability and Reliability
A DevOps engineer ensures the stability and reliability of software systems by implementing robust automation processes, continuous monitoring, and effective incident response. This proactive approach minimizes system downtime and enhances user experience, improving customer satisfaction and loyalty. The 2021 State of DevOps Report from Google Cloud and DORA identified that elite DevOps performers experience 3 times lower change failure. Hiring a DevOps engineer helps safeguard your business against costly disruptions and reputational damage.
Streamlined Infrastructure and Cost Optimization
DevOps engineers possess expertise in leveraging cloud services and IaC practices, resulting in optimized resource utilization and cost management. They can help identify and eliminate inefficiencies, such as over- and under-utilization of infrastructure, leading to significant cost savings for your business.
How Much Does It Cost to Hire a DevOps Engineer
DevOps specialists are among the top-earning developer roles globally, with a median annual salary of $160,000 in the US and $80,000 worldwide, according to the 2022 Stack Overflow Developer Survey.
However, we recommend taking a closer look at earnings in different countries. These figures reflect the average income in 2023 calculated using Glassdoor’s proprietary Total Pay Estimate model, which is based on salary data from platform users.
| Country | Salary per year, USD |
| United States | $135,000 |
| Canada | $93,000 |
| Mexico | $87,000 |
| United Kingdom | $89,000 |
| Germany | $87,000 |
| Ukraine | $55,000 |
| India | $26,000 |
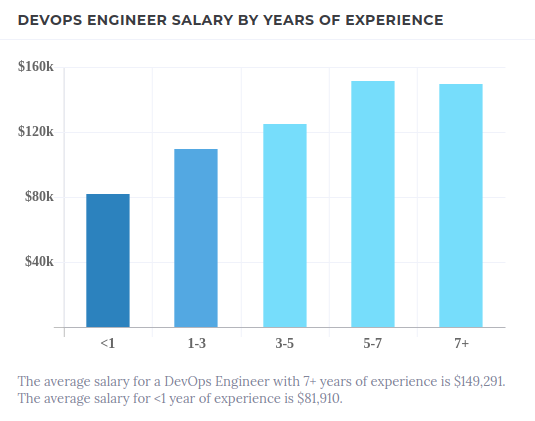
As well, as demonstrated by the average salaries on Builtin, compensation may vary depending on an engineer’s level of expertise. Thus, the picture on December 2023 is as follows:
- 1 year of experience: $81,910 per year
- 1–3 years of experience: $109,542 per year
- 3–5 years of experience: $125,219 per year
- 5–7 years of experience: $151,662 per year
- 7+ years of experience: $149,291 per year
Factors Affecting the Cost of Hiring a DevOps Engineer
DevOps practices are becoming more widespread and popular among businesses. 67% of respondents reported a 20% or more increase in cloud spending over the past 12 months. However, the salaries of specialists in this field can significantly fluctuate. So before you make this investment, it’s important to understand the factors that affect the cost of hiring a DevOps engineer.
Experience and Expertise
The more experienced and senior the DevOps engineer, the higher the salary expectations. Senior DevOps professionals often command higher compensation due to their extensive knowledge and ability to handle complex projects.
Skill Set
DevOps engineers are proficient in a wide range of tools, frameworks, and technologies, and the ability to leverage these effectively adds value to an organization. Different tool sets come with varying levels of complexity, and the demand for engineers skilled in specific tools may impact hiring costs.
Location
Geographic location plays a significant role in determining the cost of hiring a DevOps engineer. Hiring in tech hubs or areas with a high cost of living can require a large budget. For instance, according to Indeed, the average annual salary for a DevOps engineer in San Francisco is significantly higher than the national average due to the high cost of living and intense competition for talent.
Project Complexity
The complexity and scale of the projects the DevOps engineer will be handling can influence compensation. Projects with larger infrastructures or intricate requirements may require a higher level of expertise.
Certifications
DevOps certifications, such as those from AWS, Azure, or Docker, can enhance a candidate’s credibility and influence their salary expectations.
Market Demand
The demand for DevOps engineers has surged in recent years, leading to a competitive job market. The scarcity of professionals with the requisite skills and experience often drives up the cost of hiring.
Different Hiring Options for DevOps Engineers
There are several options for hiring DevOps specialists, and it can be difficult to navigate the hiring process. Traditional full-time hiring may not always be the most appropriate option, so alternative employment models have emerged, such as part-time or outsourced positions.
In-House Hiring
In-house hiring of DevOps engineers is a traditional and often preferred approach for businesses seeking long-term stability and a dedicated commitment to their infrastructure and development processes.
Full-time employees are committed to the company, and their presence contributes to a consistent and reliable approach to managing and improving DevOps processes. The internal nature of the team also allows for a more immediate response to emerging challenges, ensuring that the organization can adapt quickly to evolving requirements.
However, in-house hiring comes with its considerations. The fixed costs associated with full-time employees, including salaries, benefits, and potentially training expenses, can be higher compared to other hiring options. Additionally, while in-house teams offer stability, they might have limitations in terms of scalability, making it potentially slower to adjust the team size based on project demands.

Freelance DevOps Engineers
The utilization of freelance DevOps engineers provides businesses with a flexible and project-specific hiring solution. Freelancers offer their expertise for a defined period or project, allowing companies to tap into specialized skills without the need for a long-term commitment. This flexibility is particularly beneficial for organizations with short-term or project-based DevOps requirements.
One of the primary advantages of hiring freelancers is the ability to scale the team up or down based on the specific needs of a project. This adaptability is valuable for businesses facing fluctuating workloads or those seeking expertise for a particular phase of development. Freelancers, often well-versed in diverse technologies and methodologies, bring a fresh perspective to projects.
Outsourcing to DevOps Service Providers
Outsourcing DevOps functions to specialized service providers is a strategic move for businesses looking to optimize costs and efficiency. DevOps service providers, typically in the form of consulting firms or managed service providers, bring a wealth of experience and a dedicated team of professionals to handle specific projects or ongoing support.
Basically, outsourced teams combine the strengths of both freelancers and full-time employees. With this approach, you can get a team for long-term cooperation that will be well versed in your project. At the same time, the diversity of expertise and flexibility will be maintained by a large pool of vendor employees.
In addition, outsourcing allows organizations to focus on their core business while relying on external experts for infrastructure management, deployment, and monitoring.
Tips of Hiring DevOps Engeener
Choosing a DevOps engineer can be challenging, so we’ve prepared a few tips that will help you choose the best fit.
Define Clear Skill Requirements
Clear and comprehensive job descriptions are essential to start the hiring process off on the right foot. Outline the expected level of proficiency in key DevOps tools such as Jenkins, Docker, Kubernetes, and Terraform. And don’t forget to highlight specific responsibilities and contributions expected from the candidate.
Consider Industry Certifications
Industry certifications can serve as a valuable benchmark for a DevOps engineer’s proficiency. Look for certifications from reputable sources such as AWS, Azure, Google Cloud, Kubernetes. These certifications validate a candidate’s expertise in specific technologies and can be indicative of their commitment to ongoing professional development.
Evaluate Soft Skills
While technical knowledge is the foundation of a successful DevOps engineer, the importance of soft skills cannot be overstated. Indeed, such specialists often have to work with different teams and respond quickly to changes.
Why Choose IT Svit as a DevOps Partner?
At IT Svit, we’re your trusted DevOps, Cloud Consulting and AI partner. With a history starting in 2005, we’ve grown to a team of 200+ experts delivering end-to-end solutions globally.
Here are some advantages of hiring IT Svit as a DevOps partner:
- Cutting-edge technology mastery: Experience seamless operations with our expertise in Cloud data & AI, infrastructure, DevOps consulting, strategy & design, and security. We stay on the forefront of innovation.
- End-to-end solutions: Beyond tools, we focus on partnership. From cloud data and AI to DevOps, we engage in every project detail, ensuring your success with cost-efficient end-to-end solutions.
- Proven track record: Trusted globally, our team has successfully completed thousands of projects working with AWS, Azure, Google Cloud Platform, and bare-metal.
Ready to start the digital transformation of your business? Our outsourcing team can provide you with the best technology solutions while maintaining flexibility and cost-effectiveness.
FAQ
How Do DevOps Engineer Salaries Differ Across Geographical Locations?
Geographical location significantly influences DevOps engineer salaries. In tech-centric areas like Silicon Valley, salaries can be notably higher compared to other regions. For instance, a DevOps engineer in San Francisco might command a salary 20-30% higher than their counterpart in a city with a lower cost of living. To optimize costs, businesses might consider hiring remotely or in areas with a more favorable salary range.
What Factors Impact the Cost of Hiring a DevOps Engineer?
Several factors influence the cost of hiring a DevOps engineer. These include the engineer’s experience level, skill set proficiency, industry certifications, and the complexity of projects they will be handling. Senior-level DevOps professionals often command higher salaries due to their extensive expertise, and those with certifications from platforms like AWS or Docker may have increased market value.
Are There Cost-Efficient Alternatives to Full-Time Hiring?
Yes, businesses have cost-efficient alternatives to full-time hiring. One option is hiring freelance DevOps engineers for specific projects. Another approach is outsourcing DevOps functions to specialized service providers. Both alternatives offer flexibility, allowing businesses to scale their DevOps capabilities based on project needs without the long-term commitment associated with full-time employment. However, it’s essential to weigh the pros and cons of each option based on the specific requirements of the organization.
