In-depth approach to DevOps: Self-healing infrastructure, Big Data, AI and more…
-
5594
-
0
-
1
-
0
You have definitely heard about DevOps transformation and the benefits it can bring to your business. You know it all, yes? About cost-reduction due to transition to the cloud platforms, streamlined software delivery and reduced time-to-market due to implementation of CI/CD (Continuous Integration / Continuous Delivery) workflows and a general increase in productivity due to DevOps culture of collaboration and communication between teams.
There actually is much more to DevOps than an average article will tell you. However, in order to understand these depths, you must deal with much more complicated tasks, like building immutable infrastructure, enabling predictive and prescriptive Big Data analytics, training Artificial Intelligence and Machine Learning algorithms, enabling serverless operations, etc. Average companies can’t do this on their own, but they can order such projects from cloud vendors like AWS, GCP or MS Azure — or from Managed Services Providers, like IT Svit.
What are the benefits of more complex DevOps workflows? We will explain this below, based on our experience as one of the leaders of the IT outsourcing market in Ukraine and one of the top 10 Managed Services Providers worldwide.
Why do you need a DevOps transformation?
We all know what a Git-based workflow looks like. A developer writes a batch of code on their IDE and throws it over the wall to QA engineer for testing. If a testing environment with the required parameters is readily available, the QA specialist can start testing the code at once, if not — he has to ask an Ops engineer to configure the required testing environment. If an Ops engineer does not have anything else to do (which is very unlikely), he will configure the environment at once.
Otherwise, it will be put into the queue with the rest of the tasks (in the best-case scenario, where a ticket will be created). In the worst-case scenario, the request will be a message in a chat, which will be overlooked or quickly forgotten, so that the configuration will start with some delay, and the testing will start with a significant delay as a result. Once the testing is done, the code is thrown over the wall back to the developer for bug fixing. Rinse, repeat. Release updates once or twice a year, enjoy post-release crashes, hotfixes and other attributes of Waterfall project management.
This nightmare is well-known to all enterprise-grade software vendors and customers:
- workflow rigidity, so new features cannot be added mid-development
- exceeded deadlines, so that releases are quite slow-paced
- features become outdated faster than they are released
- products have very little interoperability
- servers have limited resources and can lag during peak loads
- long customer feedback loops
- frustrated customers, who finally switch out to more flexible competitors
The Agile methodology of software delivery was intended to solve these challenges and DevOps culture, which is the practical implementation of Agile, was introduced to provide the tooling and workflows to make this possible.

DevOps culture: don’t mix the teams, fix the mindsets
DevOps culture is actually quite hard to define with a single phrase. An inexperienced explanation would describe it as “mixing the Devs, the QA and the Ops engineers to form all-around capable teams that handle the whole process of software delivery”. This is what a person would say, who has little practical experience and understanding of what DevOps actually is. Here is how IT Svit, a Managed Services Provider with 14+ years of expertise defines DevOps culture:
DevOps methodology is a set of software delivery tools and best practices, used to combine the Dev and Ops parts of the software development lifecycle to ensure maximum performance, speed and reliability of all IT operations, workflows and pipelines to ensure uninterrupted positive end-user experience and achievement of business goals.
Thus said, the product life cycle is 90% production environment management. It would be simply strange to not take it into consideration when planning the software architecture and developing the product.
Therefore, our DevOps workflows follow the motto of “you built it — you run it”, instead of throwing the responsibility for the product performance over the wall. When we engage in a new project, our DevOps system architects discuss the best ways to operate the future product or system and ensure its optimal performance. This way, the DevOps engineers help design the CI/CD pipelines needed to turn EVERY code commit into a new product build version. This is possible due to such DevOps principles:
- Infrastructure as Code (IaC) — approach to infrastructure configuration and management, when every desired environment state is codified in textual settings files, so-called “manifests”. These manifests are processed by Terraform and Kubernetes tools and are versioned like any other code — and are launched as simply. This way, once the manifest is configured by a DevOps engineer, it can be easily launched by the developer or QA engineer. IaC also ensures that the code operates in the same environment all the way from the IDE to production, to remove the “works on my machine” byword every software engineer hates.
- Continuous Integration (CI) — simple infrastructure provisioning due to IaC enables the developers to use automated unit testing, so each new batch of code can be tested at once after the commit. This allows the teams to deliver the code in short batches and make multiple new builds of the product each day — and even turn them into releases, should they need to. This is the reason for Google Chrome, Telegram App or Facebook to update nearly every time you launch them — they finish a sprint a day. Thus said, instead of developing a new product feature for a long time in its own long repo branch, CI allows to develop in short branches, test automatically and integrate new features into the main project trunk continuously and seamlessly.
- Continuous Delivery (CD) — multiple DevOps tools like Jenkins, CircleCI, Gitlab CI, Ansible and others help automate most of the routine software delivery and cloud infrastructure management operations, by turning the output of one operation into the input for another operation.
This way the code can automatically pass all stages of the software delivery:- written in IDE and tested using the automated unit and integrity tests
- committed from IDE to the project repo,
- built and tested in the testing environment,
- moved to staging environment in case of success,
- tested by QA for regression and user acceptance,
- released to production in case of success using rolling updates to avoid downtime
- run and monitored in production.
Continuous Delivery also helps to greatly speed up and simplify the production infrastructure management, as most of the operations can be completely automated. They must not necessarily be cloud-based, as the Kubernetes cluster can be configured atop bare-metal servers or deployed to an on-prem virtualized solution like OpenStack and OpenShift.

DevOps benefits: cloud, Docker containers, microservices, API interoperability
Thus said, DevOps workflows require virtualized infrastructure to run, so public cloud like Amazon Web Services or Google Cloud Platform is their natural habitat. However, many banking and financial enterprise-grade businesses prefer to run their on-prem cloud systems to ensure data security and operational proficiency. Nevertheless, most of the startups are perfectly fine with developing and running their products on public cloud platforms.
Another important pillar of DevOps success is containerization. When your apps are running inside Docker containers — envelopes of code, containing all the needed runtime environment — your apps run exactly the same for all the customers. Besides, rebooting a container is much simpler than rebooting a virtual machine or a server, which dramatically increases the system resilience under heavy workloads.
The next benefit of DevOps workflows is the ability to split monolithic application into microservices, which communicate through APIs. This way, each product feature can be run as a separate microservice, developed independently, configured and updated without affecting the performance of the rest of the product, etc. Besides, as the microservices interoperate with each other through APIs, they can be connected to third-party modules the same way. Thus said, microservices and APIs make integration with other apps much simpler.
With the cloud transition finished, DevOps workflows and CI/CD pipelines established, all the shortcomings of Waterfall software development are dealt with:
- workflow becomes flexible and new features can be added to the project in any of biweekly releases
- predictable delivery schedule and timely releases
- shorter time-to-market for new features, ensuring competitive edge for your business
- monolithic apps are split to microservices that interact through APIs, so your product can be quite easily integrated with other parts of the software ecosystem
- cloud computing resources are scalable, so the apps always perform well
- customer feedback becomes a crucial source of input for product evolution and can be implemented in several weeks, not years
- uninterrupted positive end-user experience, leading to increased customer loyalty and brand advocacy
Most of the businesses consider their business goals achieved once the DevOps transformation we described above is complete. However, there is much more capabilities with DevOps — and now we go in deeper.
Improved DevOps capabilities for your business
Once your systems start working, you begin accumulating a trove of machine-generated and user-submitted data. This data can be incredibly beneficial for your business — and again, not in a way an average Big Data prophet would tell you. Forget about “pouring all your incoming data streams into a single data lake and then applying BI algorithms to uncover hidden patterns”. Big Data does not work that way.
The way it actually works is — specifically trained Machine Learning and Artificial Intelligence algorithms can determine normal system behavior in your data streams or normalize and visualize huge volumes of information contained in a variety of data types. Once these models are trained on historical data, they can be used to monitor the system performance and detect abnormal patterns (like a spike in system load, a beginning of a DDoS attack or a cybersecurity breach) real-time to allows your IT team to react immediately and minimize the damage or fully prevent it.
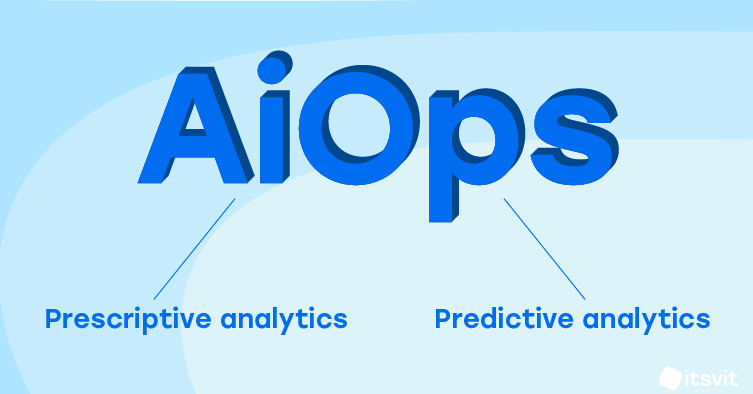
This application of Big Data analytics is called AiOps and operates under two major paradigms: predictive and prescriptive analytics. When using predictive analytics, an AI algorithm learns the normal system operation patterns, most common issues and the best response scenarios. For example, if you are running a eCommerce platform, and the peak of usage is between 5 and 8 p.m. UTC, you might want to scale the system up (spin up more instances) to deal with the load, and scale it down (terminate the instances) once the peak is gone.
Such a scenario can be configured even using your cloud platform admin dashboard. However, automated scenario will work every time, even when it is not needed — like during a holiday season, when most of the activity ceases — so it must be adjusted frequently. Quite the contrary, a trained Machine Learning model will recommend the DevOps engineer to spin up additional instances only when the CPU load will go up (even if it happens outside of usual peak time) and stop them once the peak load is over. This is what predictive analytics does, and it is much more cost-efficient and helps save a ton of effort on constant manual system monitoring and adjustment.
Prescriptive analytics works in a similar way, it just makes another step further and operates the infrastructure autonomously, only alerting the DevOps engineers when something unidentified is going on. This results in so called “self-healing infrastructure” where a failure of any container will result only in alerting the appropriate person, forming an error log with a screenshot and rebooting the faulty container without stopping the system operations even for a second. IT Svit has configured such systems for many of our SME customers, and it helped them greatly reduce the production environment monitoring complexity.
Big Data can also be applied in Industry 4.0, where edge computing and trained ML models help operate autonomous factories and facilities; in agriculture, where normalization of the data on cattle diseases and treatments for them allows the farmers to identify the illnesses and apply the correct medications faster, without the need to wait for the vet; in marketing, where a trained AI algorithm can analyze a huge influx of news data and filter out only niche-relevant for the domain owner, like showing the latest news on eLearning on an educational portal — and much, much more.
Final thoughts on in-depth DevOps features
Even standard DevOps transformation would be very beneficial for your business. Should you decide to go for a deeper dive into advanced DevOps capabilities, and implement Big Data analytics — you would reap much more advantages and cut your expenses even more. The only challenge on this way is finding a reliable IT services partner, who will be able to provide an end-to-end solution for your project.
IT Svit is such a partner, and this is proven by our leading positions in various business ratings,multiple positive IT Svit customer reviews, accolades, and acknowledgements from our partners. Should you want us to become your Managed Services Provider and help your next project become a success — contact us, we are always glad to assist!
